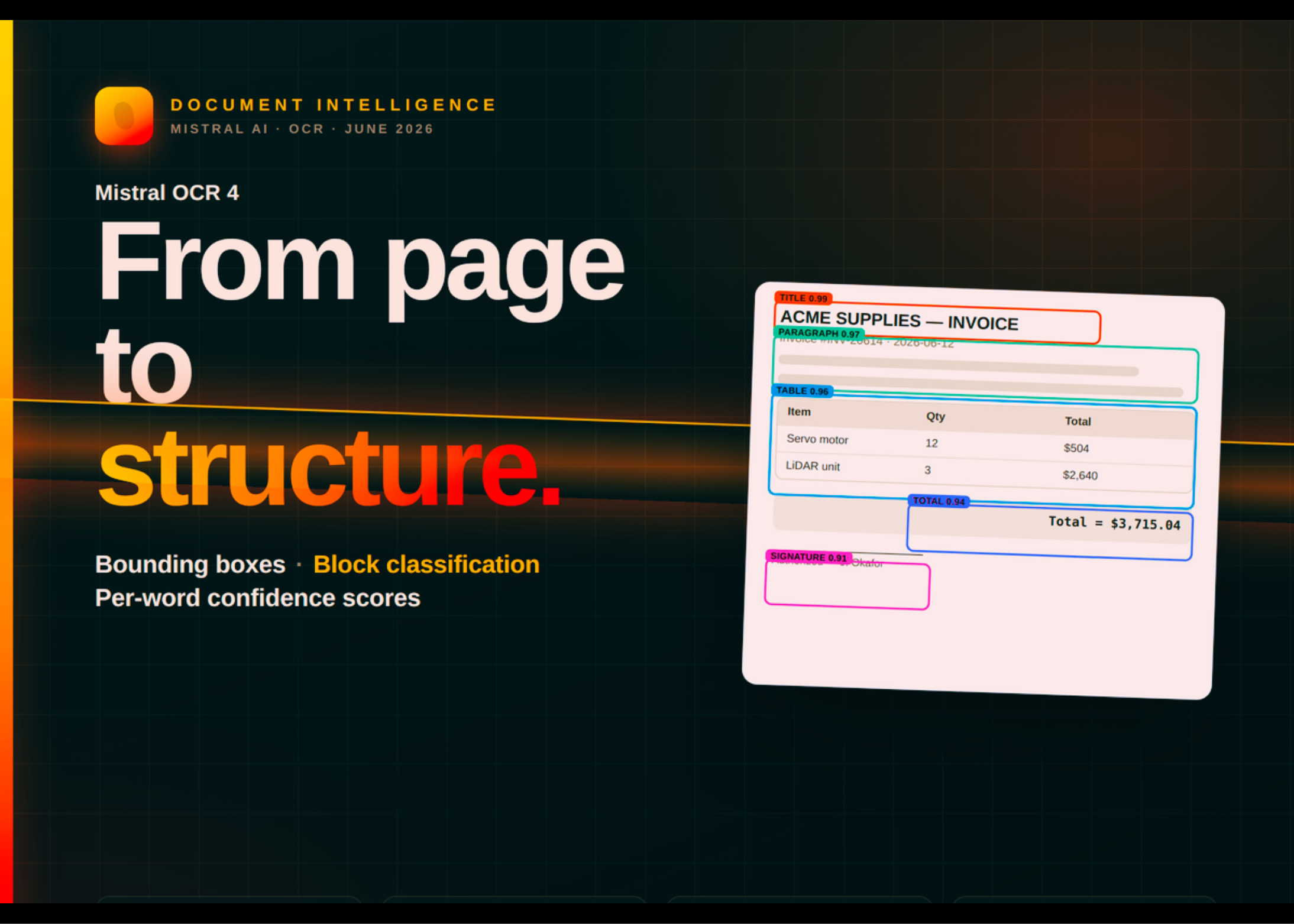
A Mistral AI acaba de lançar o OCR 4, seu mais novo modelo de compreensão de documentos. Esta versão traz bounding boxes, classificação de blocos e scores de confiança inline junto com o texto extraído — uma evolução significativa em relação às gerações anteriores que apenas convertiam páginas em texto limpo.
O modelo suporta 170 idiomas em 10 grupos linguísticos e roda em um único container, permitindo deploy totalmente self-hosted para clientes enterprise com requisitos de residência de dados e compliance.
O que mudou no OCR 4
Diferente dos OCRs tradicionais que retornam apenas texto, o OCR 4 entrega uma representação estruturada do documento inteiro:
- Bounding boxes localizam cada elemento na página
- Classificação de blocos identifica títulos, tabelas, equações, assinaturas e muito mais
- Scores de confiança por página e por palavra permitem que sistemas downstream saibam não apenas o que o documento diz, mas onde cada elemento está e qual o grau de certeza do modelo
Esse contexto extra é essencial para citações com fonte rastreável, redações automáticas e verificação com human-in-the-loop.
Formatos e deploy
O OCR 4 aceita formatos enterprise comuns: PDF, DOC, PPT e OpenDocument. O modelo é compacto o suficiente para rodar em um único container, com deploy self-managed disponível para clientes enterprise.
Performance nos benchmarks
A Mistral comparou o OCR 4 contra modelos OCR nativos de IA, modelos generalistas de fronteira, serviços enterprise de documentos e o OCR 3 anterior. Anotadores independentes preferiram o OCR 4 sobre todos os sistemas testados, com taxas de vitória médias de 72%.
Nos benchmarks automatizados:
– 85,20 no OlmOCRBench (público)
– 93,07 no OmniDocBench
– 0,98 no Crawl Multilingual (avaliação interna)
Dois cases de clientes ilustram o impacto: a Rogo reportou acurácia equivalente com custo ~8x menor e latência ~17x menor vs. parsers agentic líderes. A Anaqua mediu processamento ~4x mais rápido por página que seu fornecedor anterior.
Casos de uso
O OCR 4 suporta tanto pipelines de alto volume quanto fluxos interativos:
- Extração e parsing de documentos: Converter contratos multilíngues em markdown estruturado para indexação
- RAG (Retrieval-Augmented Generation): Alimentar blocos classificados em pipelines de busca para respostas com citações grounded
- Workflows agentic: Agentes recebem campos tipados e bounding boxes para preencher formulários automaticamente
- Pipelines com gate de confiança: Rotear regiões de baixa confiança para verificadores humanos e aprovar o resto automaticamente
- Enterprise search: Usar OCR 4 como componente de ingestão e extração de entidades em arquivos corporativos
Integração com Mistral Search Toolkit
O OCR 4 é também um componente de ingestão do Mistral Search Toolkit, agora em preview público. O Search Toolkit é o framework open-source e componível de busca da Mistral, e a saída estruturada do OCR 4 fornece inputs prontos para citação em fluxos de retrieval e avaliação.
Preço
O OCR 4 custa $4 por 1.000 páginas, com desconto para $2 usando a Batch API. Um único endpoint atende tanto extração pura quanto saída schema-driven no estilo Document AI.
Limitações
A Mistral ressalta que o OCR 4 é um modelo de compreensão de documentos, não um tomador de decisões. Ele não é indicado para diagnóstico médico, julgamento legal, decisões financeiras de alto risco, sistemas de segurança crítica, processamento em tempo real ou inputs que não sejam documentos (como áudio ou vídeo bruto).
O lançamento do OCR 4 representa um passo importante na evolução dos modelos de visão para documentos, especialmente para pipelines RAG e agentic que exigem mais do que texto bruto — precisam de estrutura, contexto e confiança mensurável.

Datalab Lança Lift: Modelo de Visão Open-Source de 9B Extrai Dados Estruturados de PDFs com 90,2% de Precisão | IA em Foco
Hollywood se Curva à OpenAI: Estúdios Rejeitam Filme Sobre Sam Altman em Meio a Parcerias Bilionárias com IA | IA em Foco

Related Posts
Figma Anuncia Ferramentas de IA para Motion Graphics, Shaders e C ...
24 de junho de 2026
Nous Research adiciona /learn ao Hermes Agent: crie skills sem es ...
24 de junho de 2026



