
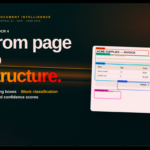
A Datalab acaba de lançar o lift, um modelo de visão open-source com 9 bilhões de parâmetros projetado especificamente para extração de dados estruturados. Você fornece um schema JSON e um PDF (ou imagem), e o modelo retorna um objeto JSON perfeitamente compatível — sem alucinações, sem retrabalho.
O lift atinge 90,2% de precisão por campo em um benchmark interno de 225 documentos e processa cada documento em uma mediana de 9,5 segundos. Para um modelo de 9B auto-hospedável, é um resultado impressionante.
Como funciona
O lift opera em duas etapas:
- Leitura visual direta: o modelo lê páginas de PDF ou imagens como entrada visual — sem OCR intermediário, sem pipeline quebradiço.
- Decodificação guiada por schema: a saída é restrita ao JSON Schema fornecido, o que elimina alucinações estruturais e garante conformidade desde a primeira inferência.
Documentos com múltiplas páginas são processados de uma só vez. Campos que cruzam páginas (como uma tabela que começa na página 3 e termina na página 5) são capturados corretamente.
Modos de inferência
O lift oferece dois modos:
- Inferência local: via HuggingFace, ideal para desenvolvimento e testes.
- Inferência remota: via servidor vLLM, recomendado para produção.
O código é distribuído sob licença Apache 2.0. Os pesos usam uma licença OpenRAIL-M modificada.
De onde vem o lift
A Datalab não é novata em OCR e extração de documentos. A empresa já mantém ferramentas open-source conhecidas como chandra, marker e surya — todas voltadas para processamento de documentos. O lift é o primeiro modelo da Datalab construído exclusivamente para extração estruturada.
O cenário competitivo
O lift entra em um campo pequeno mas ativo de modelos de extração abertos. De um lado, há modelos especializados como a família NuExtract. De outro, modelos de visão-linguagem genéricos adaptados para extração, como o Qwen3.5-9B. O diferencial do lift está na combinação de um backbone de visão-linguagem com decodificação restrita por schema — o que melhora tanto a precisão quanto a confiabilidade da saída.
Por que isso importa
Extrair dados estruturados de documentos é uma das tarefas mais comuns — e mais frustrantes — em ambientes corporativos. Faturas, contratos, relatórios financeiros, formulários regulatórios: tudo ainda depende de processos manuais ou pipelines frágeis de OCR + regex.
Um modelo open-source de 9B que resolve isso com 90% de precisão e 9 segundos por documento muda a equação. Times pequenos podem rodar localmente, sem depender de APIs proprietárias ou enviar documentos sensíveis para a nuvem.
O lift está disponível no GitHub da Datalab e no HuggingFace.

NVIDIA lança Canary-1B-v2: ASR multilíngue open-source com 25 idiomas e exportação de legendas SRT | IA em Foco
Mistral Lança OCR 4: Compreensão de Documentos com Saída Estruturada e Citações para RAG | IA em Foco
Related Posts
Figma Anuncia Ferramentas de IA para Motion Graphics, Shaders e C ...
24 de junho de 2026
Nous Research adiciona /learn ao Hermes Agent: crie skills sem es ...
24 de junho de 2026



