A Nous Research acaba de lançar um novo modo de configuração para o Hermes Agent, seu framework open-source de agentes de IA auto-melhoráveis. Chamado de Blank Slate (“tela em branco”), o modo inverte a lógica tradicional de onboarding: em vez de um agente completamente carregado com todas as funcionalidades ativas, você começa com quase nada — e habilita apenas o que realmente precisa.
O que é o Blank Slate
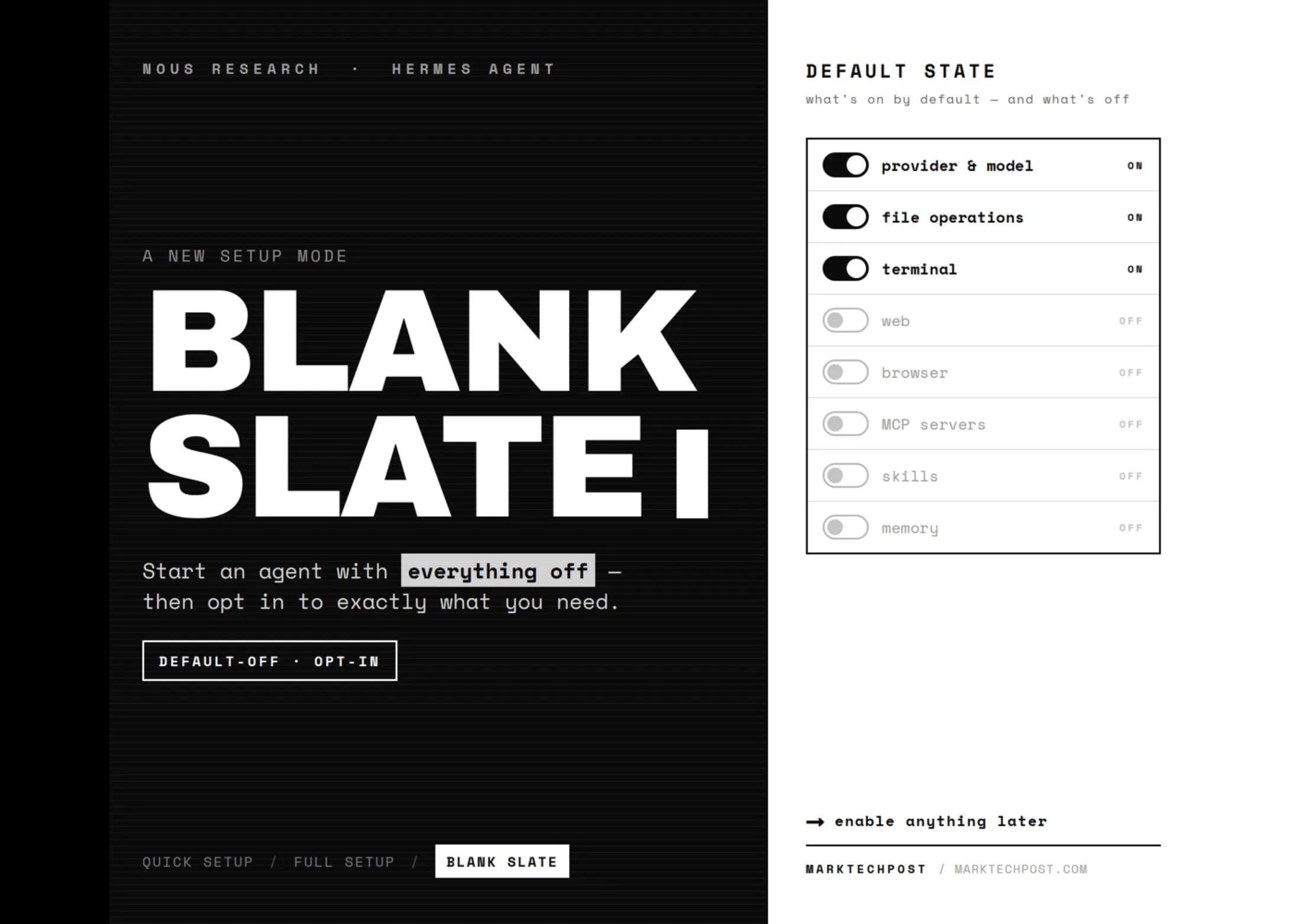
Em uma instalação limpa, o comando hermes setup agora oferece três modos de configuração:
- Quick Setup: usa o portal da Nous com login OAuth gratuito, sem necessidade de chaves API. É o caminho mais rápido e recomendado para iniciantes.
- Full Setup: você percorre cada provedor, ferramenta e opção manualmente, fornecendo suas próprias chaves. Controle total.
- Blank Slate (novo): o caminho mÃnimo. Apenas três componentes vêm ativados por padrão: provedor e modelo, File Operations (operações de arquivo) e Terminal. Todo o resto fica desabilitado.
Tudo que começa desligado no Blank Slate: web, navegador, execução de código, visão computacional, memória, delegação, cron jobs, skills, plugins e servidores MCP. Compressão, checkpoints, roteamento inteligente e captura de memória também ficam fora.
Por que o formato de configuração importa
O Blank Slate não apenas alterna funcionalidades em tempo de execução — ele grava a decisão em disco. O modo escreve uma lista explÃcita em platform_toolsets.cli e outra em agent.disabled_toolsets. Juntas, essas duas chaves fixam a superfÃcie do agente de forma permanente.
O efeito é durável: nada que você deixou de fora será carregado depois, nem mesmo após um hermes update. Uma atualização não pode reativar silenciosamente um toolset que você desligou.
A separação de responsabilidades também é clara: tokens e segredos ficam em ~/.hermes/.env, enquanto configurações não sensÃveis vão para ~/.hermes/config.yaml. O CLI roteia cada valor para o arquivo correto.
Casos de uso ideais
Três cenários se beneficiam do Blank Slate:
-
Ambientes de segurança restrita: quando você quer um agente sem acesso à web e sem navegador. O Blank Slate entrega apenas arquivos e terminal. Nada alcança a rede a menos que você adicione explicitamente.
-
Times com configuração reprodutÃvel: você fixa um toolset conhecido em todas as máquinas da equipe. Atualizações não introduzem surpresas — a superfÃcie é idêntica em qualquer lugar.
-
Desenvolvedores que constroem do zero: se você quer entender exatamente o que cada componente faz antes de ativá-lo, o Blank Slate é o ponto de partida ideal. Habilite skills, plugins e MCP à medida que cada necessidade surgir.
Comparação entre os modos
| Modo | Padrão ativo | Autenticação | Ideal para |
|---|---|---|---|
| Quick Setup (Portal Nous) | Modelo + Tool Gateway | OAuth gratuito, sem API keys | Primeira execução mais rápida |
| Full Setup | Todas as ferramentas (escolha manual) | Suas próprias chaves | Controle total e personalizado |
| Blank Slate | Provider, File Ops, Terminal | Apenas auth do provider | Segurança, minimalismo, reprodutibilidade |
Disponibilidade
O Blank Slate está disponÃvel agora no Hermes Agent. Para usar, execute hermes setup em uma instalação limpa e selecione a terceira opção. Se você já tem um agente rodando com Quick ou Full Setup, pode reconfigurar com hermes setup agent para ajustar toolkits individuais.
A Nous Research continua expandindo o Hermes Agent como uma alternativa open-source robusta no ecossistema de agentes de IA — agora com ainda mais controle nas mãos do desenvolvedor.













