O Cannes Lions 2026, que acontece entre 22 e 26 de junho na França, será palco de uma verdadeira revolução na publicidade. A NVIDIA e seus parceiros — incluindo AWS, Criteo, Higgsfield, Taboola e Alembic — vão mostrar como a inteligência artificial está transformando o marketing e a publicidade, levando o setor da era digital para a era das operações autônomas com IA.
“A era digital deu velocidade à indústria de publicidade e marketing; a era da IA está dando operações autônomas.”
Inteligência de decisão em escala empresarial
A plataforma de IA causal Alembic resolve um dos maiores desafios das empresas: provar quais iniciativas de marketing realmente geram crescimento, em vez de apenas reportar o que aconteceu.
Modelar causalidade real simultaneamente em cada canal, mercado e audiência exige uma infraestrutura de IA capaz de processar datasets enormes em rápida mudança — e é aà que entram os sistemas NVIDIA DGX Vera Rubin NVL72.
A Alembic será a primeira empresa de IA causal a usar NVIDIA DGX Vera Rubin SuperPODs para modelagem causal em escala empresarial. Com isso, executivos terão uma fonte única de verdade sobre o que realmente gerou resultados de negócio — e onde o capital está sendo desperdiçado.
Lances inteligentes em velocidade de leilão
Para anunciantes, veicular anúncios e recomendações relevantes em bilhões de transações diárias exige IA rápida, precisa e barata o suficiente para rodar em escala.
A AWS está integrando infraestrutura de nuvem, modelos fundacionais e computação acelerada por GPUs NVIDIA em uma stack coesa para a indústria de adtech. Usando o NVIDIA Triton Inference Server, a AWS oferece inferência de deep learning rápida o suficiente para caber dentro das janelas de leilão em tempo real.
A Criteo — uma das maiores redes de recomendação em publicidade digital — conseguiu um aumento de aproximadamente 2x na velocidade de treinamento de seus modelos em GPUs NVIDIA Blackwell, usando a biblioteca aberta NVIDIA cuEmbed. Essa eficiência já libera cerca de 17.000 horas de GPU por ano.
A Taboola está usando GPUs NVIDIA para alimentar o DeeperDive, seu mecanismo de respostas com IA, e estendendo essa infraestrutura para plataformas de IA e chatbots que podem gerar receita com publicidade.
Agentes de IA no fluxo de marketing
Agentes de IA estão agindo cada vez mais como colegas de trabalho digitais, assumindo tarefas de longa duração em planejamento, execução e otimização. Mas para serem usados em escala empresarial, precisam de controles adequados: salvaguardas de segurança, auditabilidade e permissões baseadas em papéis.
O NVIDIA Agent Toolkit, que inclui os blueprints NVIDIA NemoClaw e o runtime seguro NVIDIA OpenShell, fornece exatamente esses controles.
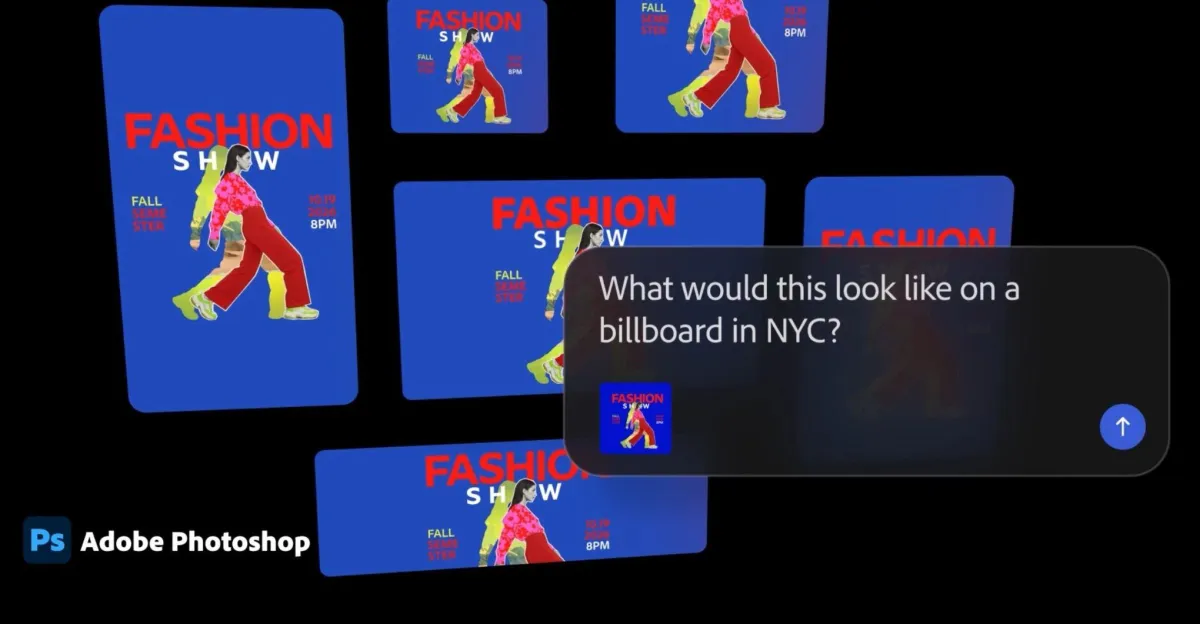
A Higgsfield AI, plataforma de geração de vÃdeo e imagem com IA, oferece agentes do Higgsfield Supercomputer que gerenciam todo o ciclo de vida da automação de marketing: da ideação da campanha ao planejamento, produção criativa, publicação e otimização autônoma — tudo em uma única interface. Os agentes orquestram grandes modelos de linguagem junto com mais de 35 modelos de imagem, áudio e vÃdeo, incluindo os modelos proprietários Soul e Soul 2.0, construÃdos sobre a arquitetura NVIDIA Blackwell.
Por que isso importa
O Cannes Lions 2026 marca um ponto de inflexão para o marketing digital. A pergunta não é mais se as empresas devem adotar IA, mas se sua infraestrutura consegue suportar a velocidade e a escala que a indústria exige. A NVIDIA está mostrando que a resposta passa por computação acelerada, IA causal e agentes autônomos trabalhando juntos.